http://93.174.130.82/news/shownews.aspx?id=213d8962-9766-49d5-9d4e-53301e8da116&print=1
© 2025 Российская академия наук
В связи с широким внедрением искусственного интеллекта (ИИ) возникли
новые вызовы, которые требуют фундаментальных исследований. Эти вызовы заключаются
в появлении новых классов кибератак – на обученные нейросетевые модели. О
планах борьбы с этой угрозой 23 ноября 2021 г. рассказал на собрании президиума
РАН по вопросам безопасности ИИ директор Института системного программирования РАН, академик РАН Арутюн
Аветисян.
По словам академика Аветисяна, были «зимы» ИИ, когда интерес
к нему угасал, но в последние 5 лет мы видим повсеместное его использование во
всех сферах, включая медицину и сельское хозяйство. По прогнозам, объем
глобального рынка ИИ в 2021 г. составит 327 млрд долларов, а в 2024 году
превысит 500 млрд. Отставание в этой области недопустимо.
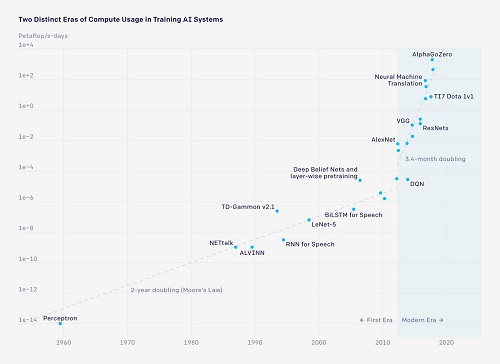
В качестве иллюстрации бума технологий ИИ Арутюн Аветисян
привел в своем докладе график роста вычислительных ресурсов, которые используются
для тренировок нейросетевых моделей (выше). Видно, что до 2005 года они увеличивались
в соответствии со средним темпом роста всей вычислительной техники, который
определяется известным законом Мура. Но потом началась «новая эра», когда
ресурсы, выделяемые на обучение ИИ, стали расти взрывными темпами.
«Только что пришло сообщение, что китайцы выложили новую
языковую модель, – сообщил академик Аветисян. – До этого самой большой языковой
моделью была GPT, разработанная в США. Она содержала 175 млрд параметров.
Китайцы выложили полностью оригинальную модель с 245 млрд параметров для
китайского языка. Есть ли для русского языка полностью оригинальная модель?
Нет. Даже наш самый передовой Сбербанк берет GPT и доучивает ее уже на нашем суперкомпьютере
Christofari, добавляя туда языковую часть русского языка».
Правда, как отметил Арутюн Аветисян, что касается самого искусственного
интеллекта, то, к сожалению, с точки зрения математики, последние достижения – это,
скорее, грубая сила, основанная на росте больших данных и суперкомпьютерных
мощностей. Математика там достаточно простая. Сильного искусственного
интеллекта, способного принимать действительно самостоятельные решения в
условиях неопределенности, пока не существует.
«Я это утверждаю и буду утверждать, что в ближайшие годы
вряд ли он появится, – заявил академик Аветисян. – Это не значит, что им не
надо заниматься. Более того, у нас есть сильные школы, которые им занимаются.
Это фундаментальные исследования, которые нужно финансировать. Но мы сейчас
живем в мире слабого искусственного интеллекта, а это то самое машинное
обучение».
Как заметил Арутюн Аветисян, с появление сильного ИИ
проблемы этики его использования станут другими, хотя, конечно, правовые вопросы
возникают и со слабым ИИ. Если врач ошибся с диагнозом, то это одна ситуация, но
если ошибся ИИ, то что тогда делать?
«Это одна из причин, почему американские модели до сих пор не
пошли в медицину, хотя они существуют уже 5-7 лет, – объяснил Арутюн Аветисян.
– Об этом не говорят, но та же IBM вложила в это направление миллиарды
долларов. С моей точки зрения, это подойдет, скорее, для скоринга (оценки кредитоспособности
– Прим. ред.) всего населения, а медицина должна работать по-другому».
Одна из «слабостей» слабого ИИ – его датацентричность, то
есть зависимость качества модели от качества данных, на которых ее тренируют.
«Данные, по которым обучается модель, могут быть испорчены, –
предупреждает академик Аветисян. – Причем очень часто говорят, что туда можно
что-то заложить. Безусловно можно, но природа ИИ такова, что это может
произойти и без закладки, если данные не полны и не точны.

В своем докладе академик Аветисян привел несколько примеров
тех рисков, к которым приводит практическое использование плохо обученного ИИ: достаточно
надеть майку – и человек становится птицей (выше), а молодой парень превращается
в певицу Дженнифер Лопес просто потому, что надел очки (ниже). При
незначительной модификации знак STOP
перестает считываться ИИ, что может привести к аварии беспилотного
транспортного средства.

Эти слабости зачастую используют для атак на ИИ. Например, иногда
в изображение, на котором могут тренировать ИИ, вносится белый шум, который
глаз вообще отличить не может, но после этого для ИИ утка превращается в лошадь.
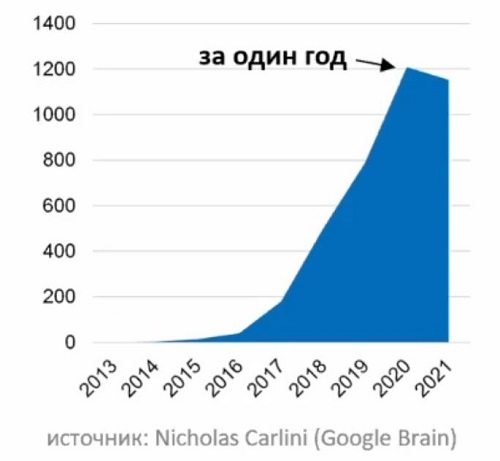
Эти проблемы в последнее время привлекают все большее
внимание специалистов. Наблюдается взрывной рост публикаций, посвященных атакам
на системы с ИИ (выше).
«Я в последний год был на нескольких конференциях, Google, Microsoft, закрытых, открытых, и от 50
до 70 % докладов были про доверенный ИИ», – подчеркивает Арутюн Аветисян.
Именно для решения этой проблемы в России организуется Центр
доверенного ИИ на базе ИСП РАН, один из шести центров, создаваемых в рамках
федерального проекта «Искусственный интеллект», который курирует
Минэкономразвития России. Победа в конкурсном отборе стала для ИСП РАН одним из
главных событий 2021 года.
«Мы из этих шести центров – единственная академическая
организация, – рассказывает академик Аветисян. – Но очевидно, что одна
организация все вопросы решить не может и с самого начала в заявке было
заложено, что мы будем создавать сообщество и, по сути, берем на себя роль научного
лидерства, когда 30–40 % задач выполняем мы, а остальные – партнеры, среди
которых «Лаборатория Касперского» и «Роскосмос» в лице ЦНИИМАШа.
В числе партнеров Центра – МФТИ, Сколтех, МНОЦ МГУ, Мехмат
МГУ, Университет Иннополис, ННГУ, ИП РАН, МСЦ РАН, ЗАО «ЕС-Лизинг»,
«Интерпроком», «Технопром».
«Будет расширяться и академическое сообщество. К нам уже
присоединился Институт психологии РАН, – сообщил Арутюн Аветисян. – И РАН может
и должна возглавить руководство такими сообществами».
Редакция сайта РАН