http://93.174.130.82/digest/showdnews.aspx?id=c8ffa787-188c-417b-8f5e-73167ee17313&print=1
© 2024 Российская академия наук
Цифровые технологии в медицине
приоткрывают результаты «клинических исследований», которые природа проводит на
нас и для нас. Биофизик Петр Федичев верит, что рано или поздно это позволит
разработать лекарство от старости, а может, и создать версию бессмертия
человека
Аналитика больших данных,
агрегирующая информацию о человеке — его генах, микробах, продуктах
межклеточного обмена, состоянии органов и тканей, реакции систем организма на
различные нагрузки, — помогает находить корреляции между процессами в организме
и развитием заболеваний. На ее основе созданы десятки предсказательных моделей,
которые постоянно совершенствуются с помощью алгоритмов машинного обучения. Еще
немного, и они начнут помогать индивидуальным пациентам, каждый из которых
получит своего цифрового аватара. Мгновенно это не произойдет: информацию
предстоит накапливать, модели — отлаживать. Но все меньше сомнений в том, что
переход к Big Data ознаменует собой вторую революцию в медицине после
изобретения микроскопов, давших врачам возможность собирать и анализировать
информацию о больных, основываясь на науке.
На каком этапе этого
драматического перехода мы находимся сейчас? Кто и как создает генеративные
модели, какие данные особенно ценят ученые и где уже используют закономерности,
найденные внутри глобальной, всеобъемлющей медицинской «картотеки»? О
возрастающей роли больших данных и искусственного интеллекта в медицине
«Эксперт» поговорил с Петром Федичевым
— выпускником МФТИ, доктором философии (PhD), основателем и научным директором
биотехнологической компании Gero, автором моделей для генеративного ИИ в
геронтологии и самых цитируемых статей об использовании больших данных в этой
области медицины.
— Кажется очень
привлекательной мысль, что колоссальные объемы неструктурированных данных о
человеке — его генах, результатах клинических анализов, биометрии с носимых
устройств — скоро произведут революцию в медицинской науке. Где мы сейчас, как
далеко от ожидаемого прорыва?
— Мы живем в очень интересное
время, когда, несмотря на все успехи медицинских наук, экспоненциальное
развитие технологий получения и обработки биомедицинских данных, стоимость
разработки новых лекарств продолжает расти и достигает сотен миллионов или даже
нескольких миллиардов долларов за каждый новый зарегистрированный препарат.
Основной причиной неудач в дорогостоящих клинических исследованиях является
отсутствие эффективности: новые лекарства отлично справляются с моделями человеческих
заболеваний у животных, но не работают на людях.
Биотехнологическая и
фармацевтическая индустрии ищут способы решения этой проблемы. Пробуют самые
разные вещи. Одна из самых разумных гипотез состоит в том, что любые
исследования на модельных организмах имеют ограниченную ценность. Что лучше
было бы иметь возможность исследовать механизмы заболеваний у людей.
Как бы фантастично это ни
звучало, медицинские исследования на людях становятся реальностью. Цифровые
технологии в медицине приводят к тому, что в мире существуют сотни миллионов
электронных медицинских данных. Десятки миллионов людей генотипированы. Это
значит, что мы можем «подсмотреть» результаты «клинических исследований»,
которые природа проводит для нас и на нас. Дело в том, что люди не одинаковы,
мы отличаемся друг от друга генетически и в зависимости от этого, попадая в
разные медицинские ситуации, имеем значительно разные шансы заболеть,
излечиться или даже умереть в результате развития тех или иных заболеваний.
Некоторые из мутаций в нашей ДНК защищают нас, а значит, могут быть имитированы
новыми лекарственными препаратами.
— Каким образом рассчитываются
корреляции между различными показателями и как строятся предсказательные
модели?
— Существует, наверное,
бесчисленное количество моделей или даже разных видов моделей, которые можно
использовать для того, чтобы искать корреляции в данных. Появление больших
данных вызвало к жизни так называемые генеративные модели — новый вид
алгоритмов, способных не выучивать или предсказывать конкретные значения
(например, параметров крови), а определять свойства распределений наблюдаемых параметров.
Это гораздо более сильная способность, поскольку такие алгоритмы могут не
только описывать данные, но создавать при необходимости новые данные,
неотличимые от существующих. В этом смысле модели становятся «цифровыми
аватарами» человека.
Если такие возможности могут
быть получены в моделях, которые используют небольшое количество параметров,
если эти параметры оказываются интерпретируемыми (понятными специалистам и
имеющими медицинский или биологический смысл), то мы сможем лучше понять, какие
факторы и как влияют друг на друга, определяя человеческое здоровье. В этом
случае модели не просто позволяют найти редкие корреляции в данных, но помогают
понять, как работает человеческий организм в разных медицинских ситуациях.
Возникает возможность проводить эксперименты, предусматривающие воздействия на
те или иные физиологические параметры, предсказывать результаты таких
воздействий на хронические заболевания на годы вперед.
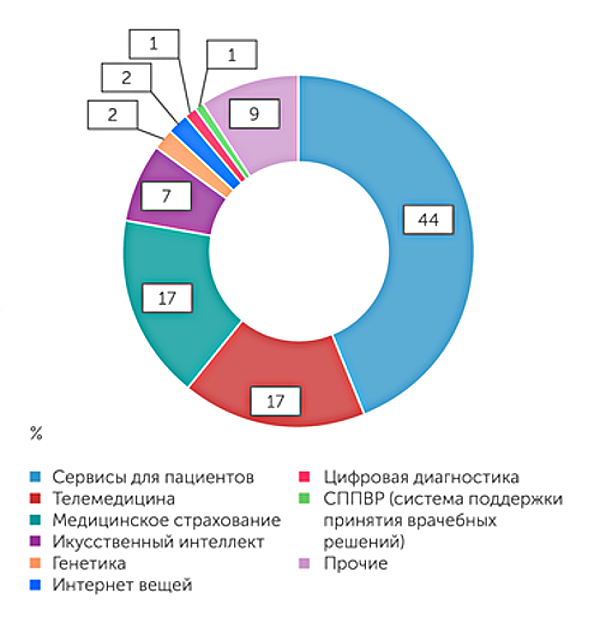
Лучший датасет — большие национальные когорты
График 1Инвестиции в цифровое
здравоохранение в России
— Какова вероятность ошибок в
моделях? Как их можно верифицировать?
— Нужно понимать, что в очень
больших данных много и ошибок. Чаще всего данные, с которыми вы имеете дело, не
собирались именно для вашего проекта, а используются дальше вместе с данными от
самых разных провайдеров. Даже если забыть на время о качестве данных, даже сто
миллионов электронных медицинских записей — это ничтожно мало по сравнению с
общим числом людей, живущих на планете (около восьми миллиардов). Это значит,
что многие из гипотез, которые вы можете сделать на основании исследования даже
самых больших доступных датасетов, окажутся неправдоподобными при попытке перенести
ваши открытия на всех людей.
Существуют способы проверять
ваши выводы в тех же данных, что у вас есть. Кроме того, в хороших
исследованиях всегда есть возможности проверить самые интересные предположения
в независимых данных (электронные медицинские записи из других стран или
районов одной страны, генетика из европейских и неевропейских когорт).
В развитых странах растет
понимание необходимости сбора качественных медицинских данных значимо больших
групп населения — создания национальных когорт. Доступ к таким данным — это
лучший способ верификации моделей.
Но даже самая красивая
гипотеза остается гипотезой до подтверждения в экспериментах на животных
(доклинические исследования) и на людях (клинические).
— Очень интересен этап, когда
модель сама начинает обучаться и развиваться. Возможно ли ее при этом
контролировать и быть уверенным, что она развивается именно так, как должна?
— При обучении модели иногда
получают неожиданные свойства. Достаточно вспомнить ChatGPT, когда нейронная
сеть, задуманная для того, чтобы дописывать предложения, оказалась интересным
собеседником, способным сдать даже некоторые профессиональные экзамены. В любом
случае модели проверяются на данных, которые модель не видела в процессе
обучения.
Воевать будет некому, а лечиться придется всем
— Кто пишет алгоритмы для
генеративных моделей?
— Современное машинное
обучение — это очень развитая область прикладной математики со своей культурой,
достижениями, методологией и специалистами. Применение этих методов в смежных
науках, таких как разработка лекарств, биология и медицина, требует
междисциплинарных навыков. Соответственно над этими моделями работают ученые из
разных областей наук. Здесь применяется целый «коктейль» методов, в том числе
из физических и инженерных наук, для того чтобы созданные модели были не только
точными в смысле предсказания, но и интерпретируемыми (понимаемыми).
— Кстати, как вы со своим
физическим образованием попали в эту область?
— В какой-то момент старшие
товарищи намекнули, что общественное внимание (а значит, и престиж,
финансирование и так далее) к физическим наукам было связано с обороной, но в
начале двадцать первого века на первый план вышли другие задачи. Развитые
страны прошли через демографический переход ― период резкого сокращения
рождаемости при одновременном росте продолжительности жизни. В итоге мы
получили рост в геометрической прогрессии рисков хронических заболеваний. Стало
понятно, что в странах первого мира скоро воевать будет некому, а лечиться
придется многим. В подтверждение этих слов можно сравнить рынок вооружений,
который к тому времени стал меньше (примерно полтриллиона долларов), чем рынок
фармацевтической индустрии (полтора триллиона долларов). Мы видели, как биотех
становился все более привлекательной сферой. Сюда шли и колоссальные
инвестиции, и вслед за ними специалисты из других областей. Если говорить о физиках,
то мы принесли с собой знания и навыки анализа явлений во времени. Те же
принципы, которые раньше использовались для предсказания затмений или для расчета
орбит межпланетных космических аппаратов (или в системах наведения), могут быть
использованы для определения механизмов старения и возраст-зависимых заболеваний.
Примеры инвестиционных
вложений в ИИ для медицины и здравоохранения в России

Работаем с тем, что есть
— Какие медицинские данные
особенно ценны для вас и ваших коллег, насколько они доступны?
— Нас интересуют так
называемые продольные медицинские данные, тое есть данные, собранные много раз
в течение жизни одного и того же человека (например, результаты его ежегодных
обследований). Сбор таких данных в большом масштабе невозможен без оцифровки,
поэтому сама возможность анализа таких данных появилась только после начала
цифровизации в медицине и появления электронных медицинских данных. Продольных
данных до сих пор не так много, как хотелось бы.
Чаще всего истории болезни
собраны в базах данных больниц или национальных системах здравоохранения. Такие
данные доступны для сотен миллионов пациентов по всему миру.
Еще есть данные биобанков — в
них собраны и электронные медицинские карты (кто когда болел, какие лекарства
принимал, анализы крови, медицинские изображения и молекулярные данные:
концентрации белков, метаболитов в крови, генетика).
— Получается, что данные
поступают из разных источников, «завернуты» в разные форматы и в массе своей не
упорядочены. Насколько влияет такая «лоскутная диджитализация» на качество
исследований?
— Прямой ответ на ваш вопрос:
мы работаем с тем, что есть, а сравниваем с биобанками, где данные собраны
особенно хорошо. А в метафизическом смысле одним из чудес, которое
демонстрирует нам современное машинное обучение, являются примеры, когда объем
данных решает вопрос качества данных. «Количество — это само по себе качество»
— эту фразу, кстати, популярную и часто цитируемую за рубежом, приписывают
Сталину, хотя вроде по смыслу ее автором должен быть кто-то из немецких
диалектиков.
— Насколько надежны хранилища медицински значимых данных о человеке?
Нет ли опасности их утечки?
— Медицинские данные относятся
к персональным и потому очень чувствительны. Существует много легальных (законы
о защите персональных данных) и технических (сертификация систем защиты данных,
деперсонализация) ограничений. Мы их сами не собираем, мы получаем или арендуем
за научные заслуги или за деньги доступ к данным, которые уже собраны и
деперсонализированы. Но мы, со своей стороны, тоже отвечаем за сохранность
данных и вынуждены проходить процедуры сертификации и так далее.
Искусственный интеллект позволяет многократно ускорить исследования биологии
человека

Ждать ли лекарства от старости
— Какие значимые результаты
уже получены с помощью искусственного интеллекта в вашей области —
геронтологии?
— На сегодняшний день еще не
существует зарегистрированного препарата против старения. Недавний обзор в Nature
говорит о том, что за все время исследований (считай, с момента расшифровки
генома человека, то есть с 2003 года), всего 40 генетических ассоциаций
превращены в лекарства против 40 болезней, в том числе 36 редких. Всего в
человеческом геноме десятки тысяч генов. Из них меньше тысячи являются мишенями
для зарегистрированных лекарств, причем в год регистрируется менее десяти
лекарств с новыми механизмами действия. Можете себе представить, сколько лет
уйдет на полноценное изучение молекулярной биологии человека? И искусственный
интеллект представляет собой способ многократно ускорить исследования.
— Ваш стартап Gero недавно
заключил контракт с одним из лидеров глобального фармрынка Pfizer. Означает ли
это, что скоро на рынок будут выведены лекарства от старения?
— Существуют ограничения в
том, что мы можем рассказывать сверх того, что имеется в пресс-релизе. Можно
сказать, что Pfizer и другие фармкомпании вопреки распространенному заблуждению
крайне интересуются проблемами старения. Сейчас интерес в большей степени
относится к связи старения и механизмов конкретных заболеваний. Дело в том, что
возраст является самым главным фактором риска для большинства значимых
заболеваний. С другой стороны, заметная часть возрастных изменений может
оказаться необратимой, и, понимая это, фарминдустрия ищет возможности отличать
те нежелательные изменения, которые трудно обратить, от тех, которые возможно
корректировать с помощью медицинских препаратов. Чем больше мы будем понимать
про механизмы старения и связь болезней и старения, тем более эффективные
лекарственные средства будут появляться на аптечных полках.
Мы надеемся, что наша работа
сближает специалистов по геронтологии, искусственному интеллекту и машинному
обучению, наукам о сложных системах и лучших в мире специалистов по разработке,
испытаниям и продаже современных лекарств. Все это потребуется для того, чтобы
разработать лекарство от старения.
— В одном из своих
исследований вы посчитали предел человеческой жизни — 120‒140 лет. Об этих
результатах писали все мировые СМИ. А что, собственно, дальше? Как эти знания
можно конвертировать в реальное повышение лимита долголетия? Предпринимаются ли
такие попытки?
— Мы написали аккуратнее:
утверждаем, что человеческое долголетие ограничено, если целью медицинской
науки будет «только лишь» борьба с конкретными заболеваниями, а не с основной
причиной тяжелых заболеваний — старением. Эта статья очень помогла нам привлечь
внимание к проблеме, в том числе со стороны фармкомпаний и инвесторов. Мы
принципиально рассказываем о наших результатах только после появления
публикаций в peer-review журналах, а потому следите за апдейтами. Они очень
скоро будут.
— Верите ли вы, что рано или
поздно Big Data и искусственный интеллект помогут создать модель бессмертия?
— Появление ИИ приведет к
огромным общественным и технологическим изменениям, многие из которых мы не
можем себе представить. Не стоит думать, что технологии будущего будут решать
именно те проблемы, которые мы сейчас считаем важными. Новые технологии
обеспечат нам новые возможности и подарят новые вызовы. Например, развитие
технологий прямого взаимодействия мозга и компьютеров с помощью ИИ может
привести к разрушению человеческой идентичности — мы сможем загружать в
компьютер наши воспоминания и переживания, сможем обмениваться мыслями и опытом
с другими. Личные границы точно изменятся не только в пространстве, но и во
времени: появится возможность переживать лучшие или самые интересные моменты
жизни людей с других континентов или даже времен. Что будет представлять собой
в таком мире личность, какие будут у нее границы и чем в таком случае будет
бессмертие — предстоит увидеть нам и выяснить нашим детям.